次世代シークエンスと遺伝疫学
今回は、次世代シークエンスの遺伝疫学的な解析について簡単に説明します。
解析は大きく分けて、
- 一次解析:Primary Analysis
- 二次解析:Secondary Analysis
- 三次解析:Tertiary Analysis
があります。
遺伝疫学が関わるのは三次解析がメインですので、一次解析と二次解析は簡単にだけ触れることにします。
一次解析について:Primary Analysis
一次解析の役割ですが、シークエンスのデータ(A, C, G, T)の組み合わせを記録したり、それぞれの塩基の質を評価するの作業がメインになります。
FASTQ fileについて

シークエンスされたDNAなどの塩基配列は、FASTQ形式のテキストベース形式などで保存されます。
Phred Quality Scoreについて
Phred Quality scoreは、DNAシークエンス用のプログラムPhredに用いられているベースコールのスコアです。
このスコアは、DNAの塩基配列の品質を表す指標として広く普及しています。
二次解析について:Secondary Analyses
二次解析は大きく分けて
- アラインメント:Alignment
- バリアントコール:Variant Calling
の2つに分かれます。
アラインメント:Alignment
アラインメントとは、DNAなどの配列の類似した領域を特定できるように並べることを言います。

参考にする配列(Reference)に照らし合わせながら、シークエンスした配列を並べる作業のことを言います。
このアラインメントには、通常はソフトウェアを使用しています。代表的なものは、以下の表の通りになります:
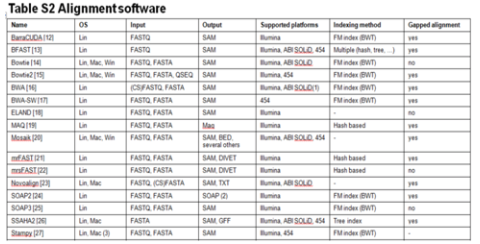
(A survey of tools for variant analysis of next-generation genome sequencing data Supplementary Data files. Brief Bioinform March 1, 2014 vol. 15 no. 2 256-278)
バリアントコール:Variant Calling
バリアントコールとは、Reference(参考にした配列)と異なる部分を示すことを言います。例えば、以下の図ですと、赤や紫などで色付けされた箇所はバリアントコールされた箇所になります。

Referenceの情報はアップデートされていることがあるので、どの時期に提示されていたものを使ったのかは記載しておく必要があります。
ほとんどのバリアントは、polymorphismsです。
三次解析:Tertiary analysis
三次解析以降は、遺伝疫学をしている疫学や統計学的な知識を使用します。行うことは、主には
- Annotation
- Variantの重要性の評価
の2つになります。
Annotationとは?
Annotationとは、バイオインフォマティクスを使用して、遺伝子(exon, intron, promoterなど)にバリアントがある場所を決定する方法です。
大量の情報ですので、プログラムを使用して行いますし、データベースも必要です。
イメージとしては、以下のようになります。
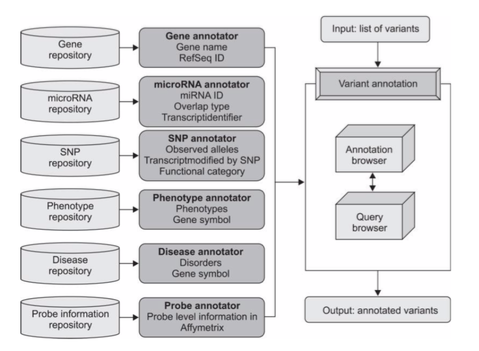
Annotationを行えるプログラムも複数あります。(A survey of tools for variant analysis of next-generation genome sequencing data Supplementary Data files. Brief Bioinform March 1, 2014 vol. 15 no. 2 256-278)
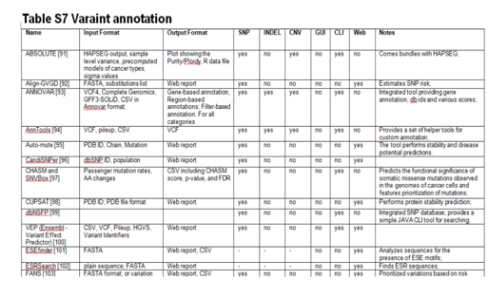
GATK
GATKとは、Genome Analysis Toolkitのことです。
近年、このソフトウェアパッケージファ開発され、variantの発見やgenotypingを中心に使用されています。さらに、データの質も保証しています。
どのVariantが重要なのか?
例えば、whole-genome scanをした場合、およそ400万のvariantがあり、そのうち2万ほどがexomeのvariantになります。
さらにそのうち、250-300はannotateされた遺伝子のloss-of-function variantであす。
ここでは少しVariantについて解説していきます。
Common VariantとRare Variantについて
Common Variant(SNPs)ですが、定義としてはAllele frequency(頻度)が0.01〜0.05以上のものを言います。
一方で、Rare Variant(SNPs)とは、0.005〜0.01以下のallele frequencyのことを言います。
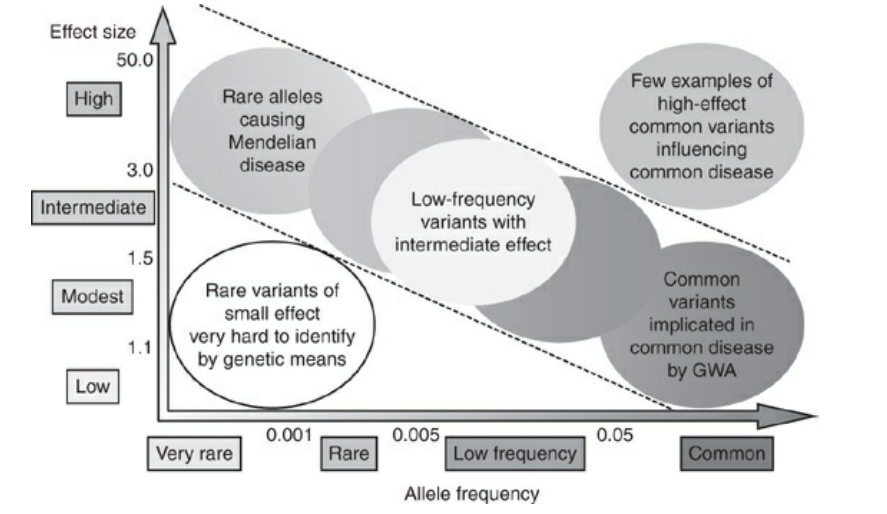
こちらはallele frequencyとvariantの頻度を見ています。
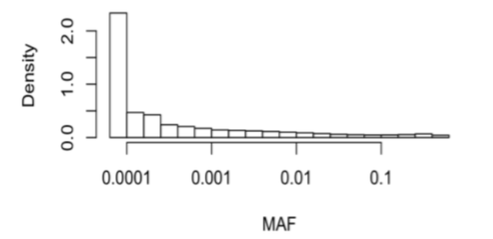
ほとんどのvariantは稀で、一般の母集団から検出しようとすると、かなりのサンプル数が必要となります。
例えば、99%以上の確率で、variantを検出するのに必要なサンプルサイズは、以下の通りになります。

Allele frequencyが小さくなればなるほど、サンプル数は大きくなるのがわかると思います。
Region based analysesについて
Region based analysisはGene-based analysisと呼ばれることもあります。
ある特定の領域(region)にvariantがあるか否か(yes/no test)、variantがどのくらいあるか(burden test)に注目して解析を行う方法です。
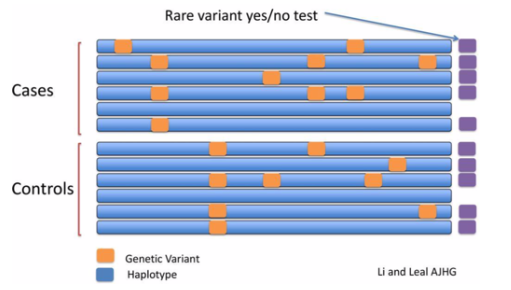
Yes/No test
Yes/No testの場合、遺伝子のある領域にgenetic variantがあるか否かをcaseとcontrolで比較します。
この場合、大事なのはvariantがあるか否かで、その数は問いません。このため、yes/no testと呼ばれています。
イメージとしては、以下の通りになります。
Burden testing
Burdenは負荷とか重荷のことを指しますが、この場合はyes/no testと異なり、genetic variantの数を計測してcaseとcontrolで比較します。
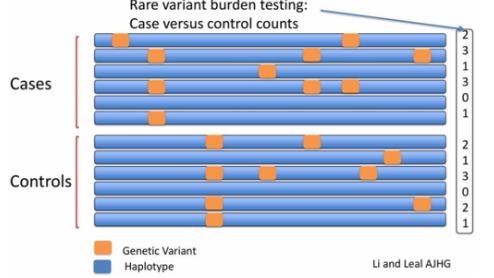
(Li and Leal (2008) AJHGより)
Family Studyについて
Family Studyはその名の通り、家系内での疾患が集積している場合に行うケンキュ方法です。例えば1つの家系で4−5人が同じ疾患に罹患している場合、家系図を作成し、可能な限り遺伝的に遠い親族までを研究対象にします。
イメージは以下の通りです:
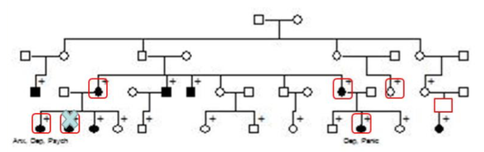
コントロールは、結婚して家系内に入ってきた人の情報を取ることが多いです。
Causality:遺伝疫学における因果関係について
通常の疫学研究と一緒で、観察研究において因果関係を示唆する際には慎重になる必要があります。
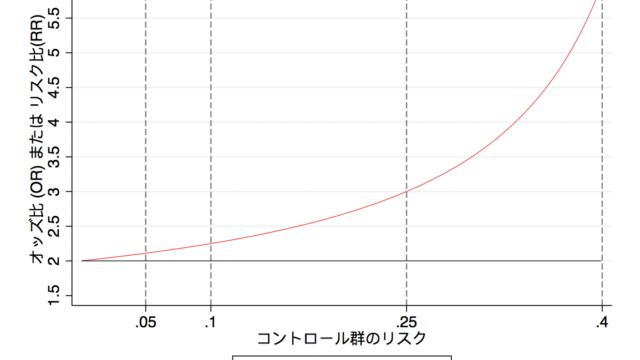
例えば、とあるGWAS (genome-wide association study)をして、ある遺伝子の領域(例えばSNPなど)と疾患の関連性を認めたとしても、必ずしもその領域が原因であったとはいえないこともあります。統計学的な有意差に基づく関連性と因果は、ある程度は区別して考える必要があります。
GWASなどで得られた知見をもとに、
- Tissue blot
- Zoo blot
を行うこともあります。
また、
- 別の母集団でも同様の結果が得られるか
- 再現性があるか
といった点も検討する必要があります。
マウス実験で、
- Knock in mutations
- Knock out gene
などを使用して検証する場合もあります。
詳しくは、以下の2本の論文に記載されているので、読んでみると良いでしょう。