今回は遺伝疫学(genetic epidemiology)でよく行われるFamilial Aggregation Studyの研究について説明していこうとおもいます。
Familyは家庭、aggregationは集積を意味します。
Familial aggregation study designは他の観察研究とも類似しており、
- Family case-control study
- Family cohort study
のいずれかがメインの選択肢となります。
今回はこちらについて、まずは表面的な点と、実例を交えながら解説していければと思います。
Familial aggregation study design
Family case-control study
Family case-control studyですが、通常のcase-control studyと類似しており、以下の手順で行います。
- Caseの定義を決める(XX病に罹患した人)
- Caseの家族歴の有無を聴取する
- Caseになりうると想定されるControlをサンプリングする
- Controlの家族歴の有無を聴取する
- Odds ratioを計算する
まず、家族歴の聴取が非常に重要です。
例えばアウトカム(case)を卵巣癌や乳癌にした場合、家族歴を聴取するのは当然ですが女性のみが対象になります。
また、同胞の家族歴を聴取する際、年が離れた同胞の場合、若すぎて家族歴を聴取するのに不適切な場合もあります。疾患毎に追加で配慮するべき点があります。
Family cohort study
Family cohort studyでは、家族歴を先に聴取して、その後にアウトカム(XX病など)が生じるのかを追跡します。このため、研究の手順としては、
- 追跡する集団を決める
- XX病の家族歴があるか否かを聴取する
- 決められた期間追跡する
- 追跡された人がXX病を発症したか否かを評価する
- Risk RatioやRate Ratioを計算する
の順になります。
この場合でも、家族歴の聴取が非常に重要になり、2ステップで行われることが多いです。
最初のステップは、両親、兄弟姉妹を含めた家族歴を聴取します。
次のステップでは、この情報をもとに疾患にかかりやすい傾向を分析します。
乳癌の例
例えば以下の表を見てみましょう。
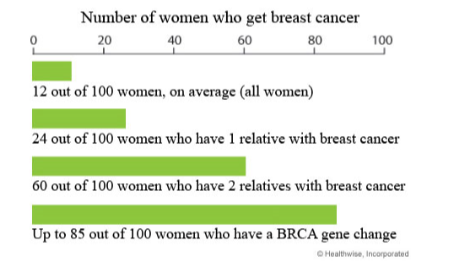
こちらは乳がんのリスクをみています。(アメリカでのデータです:American Cancer Society)
一般的な人口の女性(12/100が生涯で乳がんになる)と比較して、
- 親族に乳がん既往者が1人いると、リスクは2倍
- 親族に乳がん既往者が2人いると、リスクは5倍
- BRCA遺伝子の変化があると、リスクは7倍
に上昇するのがわかります。
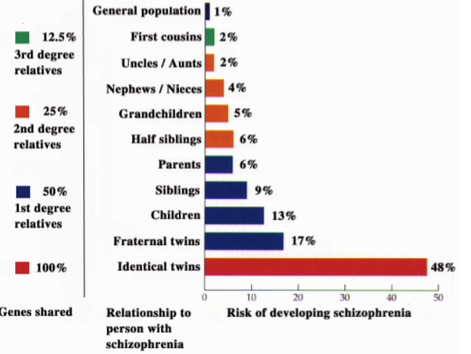
統合失調症の例
家族歴によって疾患のリスクが異なることを示した研究があります(Risch, 1990)。
こちらの表では、異なる家族歴によって統合失調症を発症するリスクが大きく異なることを示しています。
家族歴の聴取について
疾患によりけりですが、遺伝疫学における家族歴の聴取は発端者(proband)から開始することが多いです。
家族歴といって、中には記憶が曖昧な方がいたり、不正確になってしまうこともあるため、複数の回答を集め、信頼性を評価する必要があります。
(質問票の例↓)
精神科領域の疾患など、時に評価が難しいこともあります。
バイアスについて
単純に家族歴を聞くだけなので、それほどバイアスがないように感じるかもしれませんが、実はそうでもありません。
特に家族歴を聴取する場合はインタビュー形式になるため、バイアスが混入しやすいことがあります。
Recall biasの例
例えば、case-control studyをして、caseはcontrolより大家族の傾向がああると、家庭内の家族歴は当然ながらcaseの方が高くなります。
また、caseとcontrolでは、家族歴に対する思い出しバイアス(recall bias)が生じやすくなることがあります。
Selection biasについて
Genetic epidemiologyの研究では、selection biasも起こりやすいことで知られています。特にcontrolをどのようにサンプルするかが重要です。
例えば、対象集団をランダムに抽出した場合、常染色体劣性遺伝の場合は、以下のような集団が得られます。

ですが、genetic epidemiologyの研究で近しい親族のみをサンプルした場合、以下のようになってしまうことがあります。

このようなselection biasのことをascertainment biasと呼ぶことがあります。
Ascertainment correctionについて
このバイアスは”ascertainment correction”という方法で補正することがあります。
詳細は省略させていただきますが、手短に説明すると、アウトカムを有する人の中で、proband(発端者)であった人の割合(ascertainment probability:π)を計算して補正に使用します。
その他に気をつけるべきこと
家系で疾患が集積している場合、
- 遺伝子による影響
- 疾患に関与している危険因子への暴露
の双方を考える必要があります。
疾患にもよりますが、遺伝的な影響の強い病気は家族内で集積しやすかったり、親族に既往者がいるとリスクが高まるケースがあります。
後者の危険因子については、必ずしも遺伝子変異とは限らず、その家系で共通した環境的な因子のせいで、病気の発症リスクが高まってしまっている場合もあります。
これ以外ですと、
- 遺伝子と環境因子の相互作用
- バイアス
- 統計学的な偽陽性(type I error)
などの可能性も残されています。
遺伝疫学の話をすると、家系での集積を見ると遺伝子を疑いたくなりますが、それ以外の要因もあり得ることは念頭に置いておくと良いでしょう。
おまけ:Co-Morbid Family Studyについて
調査目的としていた疾患に加えて合併している疾患(comorbid disease)を評価することがあります。
具体的な例でいうと、
- 統合失調症とTourettes症候群
- てんかんと片頭痛
などがあります。
Co-morbid family studyの例
Co-morbid Family Studyの例として、Tourette症候群と強迫性障害(OCD:Obsessive Compulsive Disorder)を調査した研究があります(Pauls, Raymond, Stevenson, & Leckman, 1991)。
こちらの研究では、Tourette症候群のprobandの家族と、健常者のコントロールにおいて、Tourette症候群、慢性チック、OCDを評価しています。
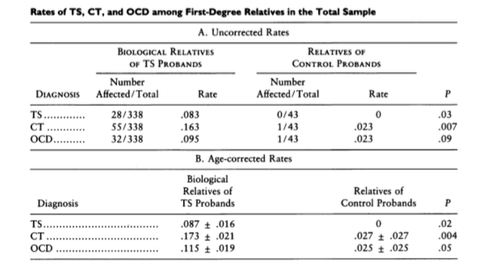
結果を要約すると、Tourette症候群の親族は、コントロールと比較してTourette症候群、慢性チック、OCDの割合が高くなっています。
まとめ
今回はFamilial Aggregation Studyについて解説してきました。
基本は疫学研究のデザインと一緒なのですが、遺伝疫学特有に注意しなければいけない点がありますので、その点の理解の補助になればと思います。
参考文献
- Pauls, D. L., Raymond, C. L., Stevenson, J. M., & Leckman, J. F. (1991). A Family Study of Gilles de la Tourette Syndrome. Am. J. Hum. Genet, 48(1982), 154–163. Retrieved from https://www-1ncbi-1nlm-1nih-1gov-1mf9loauk4bbc.han.mh-hannover.de/pmc/articles/PMC1682764/pdf/ajhg00085-0158.pdf
- Risch, N. (1990). Linkage strategies for genetically complex traits. I. Multilocus models. American Journal of Human Genetics, 46(2), 222–228. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/2301392