医療において薬剤疫学の役割は非常に高まっています。
薬剤疫学の研究の支えとなるのは、データベースの存在です。
日本でもDPCやNDB、JMDCなど薬剤疫学で使用できそうなデータベースが揃ってきていますが、国外では遥か前から類似のデータベースが開発・利用されています。
今回は、薬剤疫学とデータベース(主にアメリカ)について解説していこうと思います。


薬剤疫学における大規模データベースの役割
薬剤疫学において、近年は大規模データベースの存在が欠かせません。その理由として、疾患の特徴を捉え、薬剤疫学的な研究を行うために利用されています。
大規模データを利用と薬剤疫学
大規模データを利用する際は、主に市販後調査で利用されることが多いでしょう。利用目的は主に2つで、有効性の評価と、公衆衛生学上の意思決定の情報提供です。
市販後調査では、実際の使用率のモニター、市販後の有効性や医薬品の安全性の監視、予後の予測などを行います。
意思決定に関する情報提供ですが、薬が適切に使用されているのか、どのくらいの母集団で使用しているのか、利点と欠点のプロファイルを分析したりします。
薬剤疫学研究のデータニーズ
ここで、薬剤疫学研究には、どのようなデータが必要かを考えてみましょう。
まず、薬剤疫学の研究は薬だけをみていれば良いのでなく、疾患を把握する知識が必要です。例えば、
- 発症率・罹患率・生存率・致死率
- 疾患の病態生理、危険因子、自然経過
- アウトカムの予測因子
- 疾患の負担:DALY, years life lost, QOALYなど
がなどの知識を把握する必要があります。
また、RCTによって提供される情報は限られています。このため、”リアル・ワールド(現実世界)“でのデータを活用する必要があります。
例えば、医療や薬へのアクセス、治療ガイドラインの遵守率、薬剤のアドヒアランスの調査が該当します。
また、市販後の大規模な集団での有効性と安全性や、高齢者・合併症の多い患者などRCTでは検証できなかった集団での有効性の検討も必要になります。
薬剤疫学研究で使用されるデータベース
薬剤疫学研究で使用されるデータベースについて解説していきましょう。現在は様々なデータを利用することができ、レジストリー(患者登録)、コホート研究のデータ、医療レセプトのデータ、電子カルテデータ、サーベイランスのデータなどがあります。
データを扱う際に気をつけなければいけない点ですが、すべてのデータベースが同等に作成されているわけではない点です。それぞれのデータには、異なる強み(Strength)と弱み(Weakness)があります。
薬剤疫学の研究で使用するデータですが、ほとんどは医療サービスの研究のために特別に作られたわけではないのです。どのデータベースを使用するかの選択は、多くの場合、研究上の疑問に左右されます。時には、データベースに合わせてリサーチクエスチョンを調整する必要があります。
データを理解することの重要性
データ収集の当初の意図
まず、データベースにどのような情報が入っているのか理解する際に、データ収集の当初の意図を知る必要があります。例えば、レセプトデータなどは、医療サービスの償還記録です。サーベイランスでは、特定の疾患、医療コスト、医療リソースの利用などを解析することが多いです。それぞれのデータには主な目的がありますので、それを把握することが第1歩でしょう。
データ収集方法
次に、どのようにデータが収集されたのかを理解する必要があります。
例えば、医療レセプトデータなどは、医療費の請求などで使用されているため、ほぼ自動化された状態で収集されていることが多いです。
電子カルテの臨床情報は、臨床で必要な記録がされています。
サーベーなどは、特定の疾患を把握するため、全国やある地域で情報を収集されているケースが多いです。
調査
また、データの整理・表示について把握する必要があります。例えば医療レセプトデータですと、診断名などはICD-9/10 codeが使用されていることが多いでしょう。電子カルテなどから抽出する場合は、テキストから読み取ることになるため、エラーが起きやすいかもしれません。
その他のデータに関する考慮すべき事項
データベース内の母集団の特性を知る必要があります。
つまり、どのような集団からデータが抽出されたのかを確認します。
地域レベルのデータなのか、クリニックレベルのデータなのか、薬局レベルでのデータなのか、といったデータの出所を知る必要があります。
次に、データがどのようにサンプルされたのかを把握しましょう。サンプリングの方法としては、ランダムサンプル、階層化サンプル、コンビニエントサンプル(convenient sample)などがあります。
また、データ内の集団を、年齢、性別、居住地域、雇用形態、社会経済的状況などを特徴を確認する必要があるでしょう。
データが収集された期間も重要です。長期間集積されたデータが有利となる場合が多いですが、新しいデータが存在しないことが制約になることもあります。
また、データにもinclusion criteriaがある場合があり、特に国外のデータでは保険情報や居住地域がデータに影響しているのかを把握する必要があります。
例えば、Kaiser Permanentのデータの場合、この保険に加入している家族のみしか追跡できません。日本でいうとJMDCなども類似例でしょう。
その他、診断の検証が行われているか、薬剤の投与は確認されているのか(処方 vs. 実際の投与・内服)なども重要となります。
データベースの種類について
データベースの種類ですが、
- レセプトデータ(administrative claims data)
- 薬局データ
- サーベイランスデータ
- 電子カルテのデータ
に大きく分かれます。
主にアメリカやイギリスで使用されているデータについて解説していきましょう。
レセプトデータとしては、アメリカであればMedicareやMedicaid、NISなどが該当します。そのほかにはMarket ScanやUnited Health Careもあります。
薬局データであれば、IMS LRx、Retail pharmacy chain dataなどがアメリカにはあります。
サーベイランスであれば、NHANES, SEERなどもあります。
電子カルテのデータとしては、アメリカでは、Kaiser Permanent社のデータ、Group Health Cooperative、Geisinger、OSCERなどがあります。イギリスの場合、Clinical Practice Research Datalinkがあります。
レセプトデータについて
レセプトデータは行政請求データなどとも言われますが、元々は医療費の請求・支払いなどで使用されているデータで、それを研究用に二次利用するものです。
医療システム内の医療提供者が、被保険者に提供したサービスの記録です。データは医療費の償還の運営・記録を目的に作られています。
データにもよりますが、支払い者(保険会社など)は、このようなデータを使用して、プログラム/ポリシーを評価することに対して、インセンティブがある可能性があります。
データベースは通常、大規模(数百万人)で、複数のファイルが含まれます。このため、データを利用して研究するためには、複数のファイルからIDを使ってデータを抽出・統合する必要があります。
国内外で、これらレセプトデータを使用した研究数は、年々うなぎ登りに増えています。
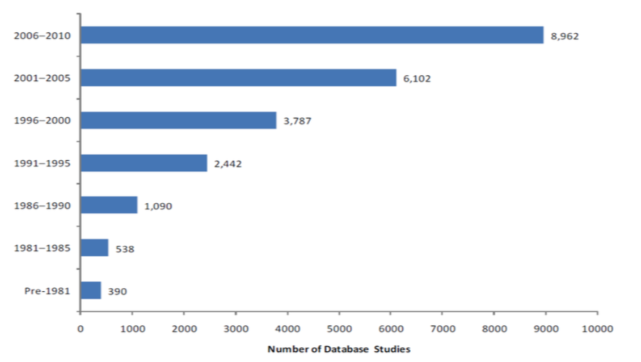
レセプトデータベースを使用する際の考慮事項
レセプトデータを使用する際、他のデータベースとリンクして利用可能かを検討する必要があります。
レセプトデータには、年齢、性別、保険情報、居住地域、診断、コストなどは含まれていることが多いですが、細かい臨床情報は含まないことがほとんどです。
このため、検査値や診断検査の結果データへのリンクや、死亡率データやカルテへのリンクが可能かを確認すると良いでしょう。
特に、重要な交絡因子に関するデータ(喫煙、食事、運動など、患者のライフスタイルに関する行動)は含まれていないことが多いです。そのほかにも、人種、SESといったデータも含まれていないことが多いです。
また、診断や処置コードには制限があります。
本当に正しい診断なのか、単に重要度の低い診断を除いて便宜的に使用された診断なのか、またそれらの感度・特異度がどうかを検討する必要があります。
さらに保険対象外のサービスと医薬品は通常除外されています。市販薬(OTC薬)などの情報や、民間療法のデータは含まれていません。
当たり前ですが、保険情報のデータの場合、保険に加入していない人のデータは含まれていません。
メディケアやマーケットスキャンといったレセプトデータを使用した例も沢山あります:
- メディケア1:Li S et al. Clinical Epidemiology 2012;4:87-93
- マーケットスキャン2:Dusetzina SB et al. Breast Cancer Res Treat. 2013;137:285-96
レセプトデータの強みと限界
レセプトデータを使用する強みですが:
- データベースのサンプル数が多い:一般化可能性の向上、ランダム誤差が小さい
- 縦断研究が可能
- 発生率、有病率に関する人口レベルの統計を生み出すことが可能
などがあります。
一方で、レセプトデータの欠点ですが、
- 交絡因子に関する情報が不十分
- 喫煙状態、アルコール摂取量、BMI、検査値など不明なことが多い
- Confounding-by-indicationの可能性
- 支払い請求を提出した場合にのみデータが収集
- 医療機関に受診しない人の情報なし
- 処方指示やOTC薬の使用に関する情報はない
などがあげられます。
薬局データベースについて
薬局データベース(Pharmacy database)では、地域の薬局のデータを利用しています。データベースの管理は:
- 大規模小売チェーン薬局
- IMS LRx
からのデータとなります。
処方薬の請求データとリンクしている可能性があります。例としては、
- CVSとCVS/caremark
- WalgreensとWalgreens Health Initiative、Medicaid
があげられます。
アメリカ以外ですと、薬局データベースには、他のデータソースにリンクされた薬局調剤記録が含まれる場合があります(例えば、入院、医師の診察など)。日本のNDBも院外薬局に関して類似の形式をとっています。
薬局データベースで行える研究
薬局データベースで行える研究の代表例を示していきます:
- 薬剤の使用パターンやアドヒアランス
- 薬剤師ベースの介入を評価:カウンセリングが服薬アドヒアランスに及ぼす影響
- ドクターショッピングやポリファーマシー
- 破棄された処方箋
などの調査に応用できます。
薬局データベースの強みと限界
薬局データベースの強みですが、
- 薬の用量や用法に関する情報が分かる
- 処方薬以外の情報も分かる
- サンプルサイズが大きく、誤差が小さくなる
- 場合によっては縦断研究が可能
などがあげられます。逆にこのデータベースの弱みですが、
- 他の薬局で処方された処方箋のデータがない可能性がある
- 通常は診断情報を利用できない
- 請求データまたは電子医療/健康記録にデータがリンクされていない限り、健康結果に関する情報が分からない
- 健康状態に関する情報は最小限:喫煙、アルコール摂取量、BMI、検査値など
- 一般に市販薬の使用に関する情報はない
サーベイランスデータ
サーベイランスデータでは、様々な目的で調査されたデータですが
- 疾病の発生率と有病率
- 健康状態、医療へのアクセス、
- 国民健康目標の進捗
- 医療サービスの提供と利用や医療コスト
- 病気の生存率と死亡率の統計
などを扱っています。サーベイランスデータの種類も様々で、例えばアメリカの場合
- NHIS: Health interview survey
- NHANES
- Health care survey
- Vital statistics
- SEER: Surveillance, Epidemiology and End Results
- IARC
- MEPS: Medical Expenditure Panel Survey
- HCUP: National Inpatient Sample
などがあります。
これらのサーベイデータを使用した研究の例は、以下のものがあります:
- NHANES3: Menke A et al. JAMA 2015;314:1021-1029
- NHANES4: Mercado C, et al. Plos one 2018;13:e0193756
- SEER5: Zhu J et al. JAMA 2012;307:1593-1601
- IARC6: Katz AJ et al. 2014.
サーベイランスデータの強みと限界
サーベイランスデータの強みですが、以下の点があげられます
- 住民ベース(一般化可能)
- 疾病の発生率、有病率、生存率および死亡率、治療の利用、健康上のアウトカム、および/または医療サービスのコストの推定
- SEERデータベース:データが細やかでディケアデータへのリンク可能
などがあげられます。
欠点については、以下の通りです:
- 一部のデータは横断データのみ(追跡データなし)
- 疾患の再発または進行に関する情報の欠如
- 細分化されたデータが提供されない場合がある
- 交絡因子(喫煙、ダイエット)に関する情報が少ないことも
などがあげられます。
電子医療記録のデータベース
電子医療記録のデータベースでは、医療システムからデータを収集します。
請求や管理の目的で使用されることが多いが、患者の治療や管理、カルテのデータも使用されることが多くなってきています。
医療現場で使用されたデータのため、患者、診断、治療に関するより詳細なデータがあります。
一方で、データの数は他のデータベースより劣ることがあるため、一般化可能性に対する懸念があります。
電子医療記録データベースの例
電子医療記録データベースの例として、以下のデータベースがあげられます:
- Kaiser Permanente; US(例:Chao et al. Annals Oncol 2014;25:1821-9)
- Clinical Practice Research Database: UK(例:Schmiechowski et al. Diabetes Care 2013;36:124-9)
- Oncology Service Comprehensive Electronic Records (OSCER): Hernandez RK et al. Breast Cancer Res Treat 2014;146:637-46.
電子医療記録の強みと限界
電子医療記録の強みですが、
- サンプル数が大きければ、一般化可能性が向上
- 発生率の推定に役立つ
- 医薬品の安全性試験の実施に適している
- 治療に関するより詳細な情報(例えば薬物用量)
などがあげられます。一方で、制限事項ですが、
- 臨床情報の収集が医療機関に依存する
- そのシステム内の患者に限定される
- 地理的な制約もある
- 特定のネットワークのみの結果にある可能性がある
などあげられます。
総じていうと、医療に関連する情報は取りやすいですが、一般化可能性に関して難がある場合が多いように思います。
最近では、レセプトデータと電子医療記録を連結する試みもされているようです。
おわりに
今回は、薬剤疫学でよく使用されているデータベースについて解説しました。
次回は、臨床試験など薬剤疫学と産業について少し説明しようと思います。
参考文献
- Li S, Peng Y, Weinhandl ED, et al. Estimated number of prevalent cases of metastatic bone disease in the US adult population. Clin Epidemiol. 2012;4:87-93. doi:10.2147/CLEP.S28339
- Dusetzina SB, Alexander GC, Freedman RA, Huskamp HA, Keating NL. Trends in co-prescribing of antidepressants and tamoxifen among women with breast cancer, 2004–2010. Breast Cancer Res Treat. 2013;137(1):285-296. doi:10.1007/s10549-012-2330-z
- Menke A, Casagrande S, Geiss L, Cowie CC. Prevalence of and Trends in Diabetes Among Adults in the United States, 1988-2012. JAMA. 2015;314(10):1021-1029. doi:10.1001/jama.2015.10029
- Mercado CI, Gregg E, Gillespie C, Loustalot F. Trends in lipid profiles and descriptive characteristics of U.S. adults with and without diabetes and cholesterol-lowering medication use-National Health and Nutrition Examination Survey, 2003-2012, United States. PLoS One. 2018;13(3):e0193756. doi:10.1371/journal.pone.0193756
- Sharma DB. Carboplatin and Paclitaxel With vs Without Bevacizumab in Older Patients With Advanced Non–Small Cell Lung Cancer. JAMA. 2012;307(15):1593. doi:10.1001/jama.2012.454
- Katz A, Kang J. Stereotactic body radiotherapy with or without external beam radiation as treatment for organ confined high-risk prostate carcinoma: a six year study. Radiat Oncol. 2014;9:1. doi:10.1186/1748-717X-9-1